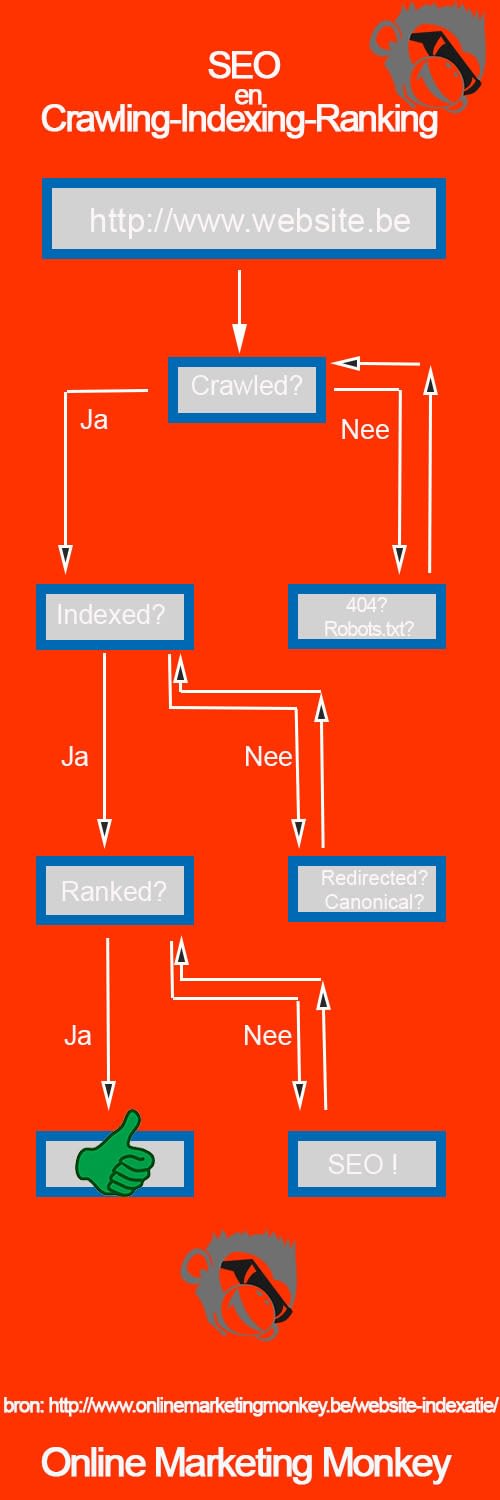
SEO website indexatie

1 van de 3 hoofdtaken van een zoekmachine is website indexatie, in dit artikel leer je daar alles over. Na crawling en voor ranking komt website indexatie.
Je website kan enkel gevonden worden als de webpagina’s geïndexeerd zijn door de zoekmachines. Als je webpagina’s niet geïndexeerd zijn kan die geen
organisch SEO zoekverkeer aantrekken..
Je moet daarom wel weten welke pagina’s Google en andere zoekmachines niet indexeren. Als dat probleem is opgelost gaat je SEO-positie weer een boost krijgen.
De 3 hoofdfuncties van een zoekmachine
Zoekmachines zoals Google doen 3 grote taken:
- Crawling
- Indexing
- Ranking
Dat betekent dat de zoekmachine in 3 fases werkt:
- Online web-content zoeken op het internet (=crawling ofwel fase 1)
- De gevonden web-info catalogiseren (=indexing ofwel fase 2)
- Een zo goed mogelijk antwoord tonen in de zoekresultaten (=ranking ofwel fase 3)
Fase 1: Crawling
Crawling lijkt eigenlijk een beetje op een metro-netwerk, daarom gebruiken we dit als hulpmiddel.

- Elke metrohalte is een unieke webpagina, video of afbeelding
- De weg die de metro neemt is de link
- Het metroplattegrond is het internet
- Om alle stopplaatsen (webpagina’s) te bekijken gebruikt de metro (zoekmachine) de meest geschikte weg (links)
Hyperlinks verbinden dus het world wide web en zo geraakt de zoekmachine aan de miljarden webcontent. Google gebruikt spiders of Google-Bots om de content te doorzoeken. Websites worden enkel bezocht als ze gekend en te vertrouwen zijn. Als de bot een nieuwe URL vindt, wordt er op die pagina gecrawld.
Spiders en bots gaan van link naar link naar link en sturen de gevonden informatie door naar de datcenters. Als de webpagina niet verbonden staat met andere web-content kan het niet geindexeerd of gecrawld worden en dat noemen we een “wees” of “orphan page”. Deze pagina’s zullen niet in de search results tevoorschijn komen.
Elke website heeft een crawl budget. Grote websites met honderd duizenden URLs zullen niet volledig gecrawld worden door Google. Het is daarom ook belangrijk dat jij als grote site de voornaamste URLs laat crawlen.
De crawlbaarheid (of crawlability) kun je verhogen door:
- Duidelijke structuur in je site
- Heldere interne links
- Vermijd kapotte hyperlinks
- Geen niet-crawlbare content hebben.
Fase 2: Indexering
De nieuwe of bijgewerkte webpagina’s die de Google-bot heeft gevonden in de vorige stap worden allemaal in een enorme database geplaatst. Deze vormen een basis voor website indexatie. Het zoekproces start met een lijst van URL’s van eerdere zoekprocessen en wordt aangevuld met de sitemap-data
Al deze sites en gevonden hyperlinks worden doorzocht door de Google-bot en daarna opgenomen in de lijst van te crawlen pagina’s. Om de index te actualiseren worden nieuwe website, bijgewerkte pagina’s en broken backlinks geanalyseerd.
Fase 3: Ranking
Na het vinden en indexeren van de webpagina’s volgt stap 3, de ranking. Alle gecrawlde pagina’s worden verwerkt in een enorme index. In die index worden alle gevonden woorden, meta informatie en de locatie van de pagina opgeslaan. Als een surfer een zoekwoord intypt in een zoekmachine wordt heel de mega-index doorzocht en de meest relevante resultaten worden meteen in de zoekresultaten weergegeven.
Kort samengevat, als de URL is geïndexeerd is deze vindbaar en kan hij weergegeven worden in de zoekresultaten.
Het belang van een technische SEO-audit
Een zoekmachine werkt in 3 stappen zoal hierboven uitgelegd. Crawling, indexering en ranking. Het kan gebeuren dat een website niet gecrawld of geïndexeerd kan worden, het gevolg daarvan is dat de webpagina niet kan gerankt worden en de zoekresultaten. Dit gebeurt vaak onbewust.
Wat er ook kan gebeuren is dat een website wel word gecrawld en geïndexeerd maar dat de content niet wordt begrepen door de zoekmachine. Dit zal zorgen voor een lage ranking en weinig organisch zoekverkeer.
Om deze problemen te vermijden is het nodig om regelmatig een SEO-audit uit te voeren. Een SEO-audit toont je welke webpagina’s niet geïndexeerd kunnen worden door een crawl-probleem of een indexeringsprobleem. Eenmaal je weet waar het probleem zit kun je dit gerichter op lossen.

Website indexatie controle tools
Indexatie-ratio
Een URL kan enkel in de zoekresultaten komen als het geindexeerd is door de zoekmachines. Daarom moet je zeker weter hoeveel URL’s van een website Google heeft opgenomen in haar index. Deze verhouding noemt de indexatie-ratio. Je kunt dit uitrekenen door het aantal geindexeerde URL’s te delen door het totaal aantal URL’s.
Dus:“aantal geindexeerde URL’s” / “totaal aantal URL’s”=“Indexatie-ratio
In de onderstaande figuur kun je 3 mogelijke indexatie-ratio scenario’s zien:
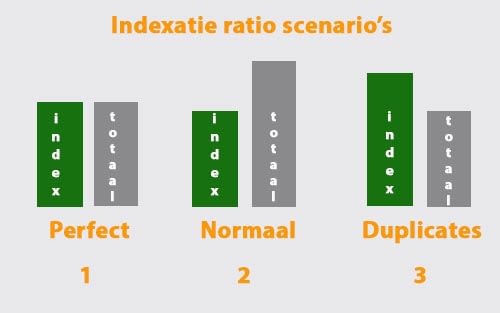
- Het eerste scenario is perfect, alle URL’s van de website zijn ook geïndexeerd door Google.
- Het tweede scenario is normaal en daarom ook de meest voorkomende. Google heeft niet alle URL’s geïndexeerd. Er zitten dus minder webpagina’s in de index dan dat er in het totaal op de website zijn. Sommige goed geoptimaliseerde SEO-websites doen dit zelf via robots.txt file.
- Als laatste heb je scenario 3. Er zitten meer pagina’s in de index dan het totaal aantal URL’s op de website. De oorzaak hiervan is duplicate content
Wil je weten hoeveel URL’s van je website in de index van Google zitten? Dit kun je doen om het te weten komen:
Site
De eerste mogelijkheid is via Google. Je typt in de zoekbalk “site: en de naam van de website er meteen tegen. Bijvoorbeeld “site:onlinemarketingmonkey.be”. Je zult het aantal resultaten zien staan. Vertrouw deze manier nooit helemaal, deze resultaten durven wel eens te wijzigen.

Bij deze zoekopdracht op Google.be was het eerste resultaat 310, na even scrollen was het resultaat plots 298. Als we dezelfde zoekopdracht in Bing en Yahoo deden kregen we 548 resultaten. Met al deze resultaten krijg je wel een beeld hoeveel geïndexeerde pagina’s er ongeveer zijn. Bij deze zoekopdracht zal dit rond de 300 liggen.
Search Console
In Google Search Console kun je gaan kijken hoeveel webpagina’s er nu echt zijn ingediend en geïndexeerd. Dat kun je zien bij “dekking” > “Ingediend en geïndexeerd”. We hebben gebruiken nog steeds hetzelfde voorbeeld als daarnet en hier kun je zien dat de score ongeveer overeenkomt met de site-opdracht. De score staat hier op 284 en via de de site-opdracht kwamen we op 300.

Sitemap
We blijven even in de Search Console en gaan kijken bij “sitemaps”. Hier zien we dat het resultaat op 298 pagina’s in de index staat. Dit is dus maar een klein verschil met de 284 hierboven. Wilt dit zeggen dat de sitemap-data in GSC niet correct is? Wij leggen het hieronder even uit:
De sitemap wordt verstuurd via de Google Search Console en dit helpt om de structuur van de website beter te begrijpen. Bij dit proces kan het gebeuren dat er nieuwe URL’s worden gevonden die tijdens het normale crawlproces niet zijn opgepikt.
Sitemaps vertellen welke pagina’s er moeten gecrawld worden maar, het is dus mogelijk dat niet alle webpagina’s zullen gecrawld of geïndexeerd worden door een search engine. Het is dus eerder een advies-tool.
Analytics
De laatste mogelijkhijd is Google analytics, je kunt dit bekijken bij “Rapporten” > “Acquisitie” > “Search Console” > “bestemmingspagina’s”. Je zult zien welke landingspagina’s SEO-verkeer ontvangen. Het getal toont hoeveel unieke pagina’s minstens 1 bezoek hebben gekregen van de google-crawler. Deze keer staat er 340 maar dit getal kan elke keer stijgen. Als je dit getal maandelijks bekijkt kan het een inzicht geven of je webpagina’s meer organsiche bezoekers krijgen.
Let op,dit cijfer is niet het exact aantal geïndexeerde webpagina’s maar het toont je hoeveel URL’s er al 1 bezoek hebben gekregen van de zoekmachine. Dat is eigenlijk veel interessanter en hier vertellen we waarom:
Indexcijfers vertellen enkel of het in de index is geraakt, dat is goed maar dat wilt niet zeggen dat je webverkeer hebt gehad.

Niet geïndexeerde URL’s opsporen
Hoe kan je dan niet-geïndexeerde webpagina’s opzoeken? Search Console en site:-opdracht vertellen daar namelijk niets over. Het is dan ook moeilijker dan gedacht.
- De eerste oplossing is elke webpagina afzonderlijk opzoeken door de “site:commando” manier. Het vergt heel veel tijd zeker als je duizenden pagina’s moet controleren
- De tweede optie is de opdracht “inurl” of “info”, Dit is even tijdrovend zoals de site:commando
- De snelste optie is een combinatie van een (betalende) SEO-tool (bv: Screaming Frog,URL profiler) en Excel. Ik leg even uit hoe het werkt:
- Scan eerst al je URL’s van de website met Screaming-Frog.
- Via URLProfiler kun je automatisch per pagina van je sitemap checken of die geïndexeerd is, dat kan met de functie “indexed in Google”.
- Je opent Excel en gebruikt de functie “=ALS.FOUT(VERT.ZOEKEN(A2;F:F;1;0);”Niet geindexeerd”). Excel zal zelf de pagina’s die niet in de index staan zoeken.
- Zo heb je een beeld van de website indexatie. In het voorbeeld zijn dat er 9, waarvan het logisch is dat ze niet opgenomen zijn maar daar komen we nog op terug.
Het is beter om ervoor te zorgen dat elke pagina high-quality content en veel backlinkshebben, dan moet je niet alle individuele non-indexed pages overlopen. Google schenkt geen waarde aan de niet-geindexeerde pagina’s, dus de pagina’s die niet kunnen ranken of bezoekers kunnen aantrekken.
Waarom zijn bepaalde webpagina’s niet geïndexeerd?
Nieuwe webpagina’s worden niet enkel gevonden door links via andere sites maar ook via de ingediende XML-sitemaps in de search console.
Om te kijken of de pagina voldoende waarde heeft voor de surfers en hun zoekopdrachten crawlen de engins de pagina’s. Als de pagina’s relevant genoeg is komen ze in aanmerking voor de indexatie.
Sommige webpages zijn niet geindexeerd door verschillende redenen:
Tijdgebonden oorzaken
- Als de pagina laag in de search results staat gerankt (bv: positie 725) kan het lijken dat ze geen index-status hebben.
- Als de website nieuw is kan het even duren voor de Google-bot deze heeft gevonden. De oplossing hiervoor is een link van de nieuwe website plaatsen op de al geïndexeerde website. Zo zal de Google-bot sneller de nieuwe website opmerken
- – Heb je net een sitemap ingediend of nieuwe URL’s? Het duurt even voor alle pagina’s geïndexeerd zijn dus wees geduldig
Technische redenen
- Soms kunnen zoekmachines niet aan pagina’s omdat ze te “diep” zitten weggestopt in de site. Dit kan opgelost worden door internal linking. Je houdt de naam zo dicht mogelijk bij de domeinnaam of je plaatst links naar verdere pagina’s op je homepage. .
- Je kunt ook per ongeluk de bots verbieden door de pagina te crawlen met je robots.txt file. Dit hebben we al eerder aangehaald.
- Nog een reden kan duplicate content zijn. Dit is het makkelijkste uit te leggen via een webwinkel. Stel je hebt 100 artikelen te koop en hebt een productpagina voor al deze verschillende producten. Als er heel weinig verschil is tussen deze pagina’s zoals de kleur of een technisch detail, kan het zijn dat de search engines denken dat dit dezelfde pagina is. Zorg dus altijd voor een verschil!
- Is je website zowel toegankelijk met als zonder “www”. De index zal hem 2 keer tellen terwijl de sitemap hem maar 1 keer zal tellen.
- Hetzelfde voor URL’s met http & https
- Als de content oud is zal die nog een soft 404’s hebben, in plaats van 401 of 301.
Andere oorzaken
Google hanteert de sitemap als een soort website-platform om andere URL’s te ontdekken, maar bepaalt niet wat er daarvan wordt geïndexeerd of juist niet wordt geïndexeerd
Het kan dus zijn dat de map URL’s bevat die de surfers niet kunnen zien in de search results omdat de engines de webpagina niet kwalitatief genoeg vonden voor de relevante zoekopdracht.
Google indexeert niet alle URL’s uit de sitemap omdat ze ervan uitgaat dat de geïndexeerde URL’s als voldoende representatief worden beschouwt, met redenering dat met meer geïndexeerde URL’s de search results niet beter zullen worden. Dit zijn Google hun eigen woorden:
“We indexeren miljarden webpagina’s en proberen dit aantal voortdurend te verhogen. We kunnen echter niet garanderen dat we alle pagina’s van een site crawlen. Google crawlt niet alle pagina’s op internet en we indexeren niet alle pagina’s die we crawlen. Het is volstrekt normaal dat niet alle pagina’s op een site worden geïndexeerd”.
Samenvatting
Je webpagina’s niet laten onderzoeken door zoekmachines is nadelig. Je webpagina’s zullen niet vindbaar zijn en je SEO-positie zal niet goed zijn. Het niet laten indexeren van je website kan verschillende oorzaken hebben. Verbeter je website door bovenstaande adviezen te volgen. In de onderstaande infographic leggen we het verband uit tussen SEO, crawling, indexering en ranking.